


High-Performance Java Persistence Tips
Introduction
- In this blog post, I’m going to show to you the various high-performance Java Persistence optimization tips that will help and enable you to get the most out of your data access layer.
- A highly efficient data access layer requires a lot of knowledge about the database internals, JDBC, JPA, Hibernate, and this blog post summarizes some of the most significant techniques you can be used to optimize your enterprise application.
-
SQL statement logging
- If you are making use of a framework that generates statements on your behalf, you should make sure to always validate the effectiveness and the efficiency of each of the executed statement. A testing-time assertion mechanism is a lot better because you can catch N+1 query problems even before you can commit to your code.
-
Connection management

- Database connections are very expensive so you should always use a connection pooling mechanism.
- Because the number of connections is given by the capabilities of the databases cluster, you need to release these connections as fast as possible.
- In the performance tuning, you always have to measure, and also setting the right pool size is no different. A tool like FlexyPool can help and enable you to find the right size even after you deployed your application into the production.
-
JDBC batching
- JDBC batching enables us to send multiple SQL statements in a single database roundtrip. The performance gain is highly significant both on the Driver as well as the database side. PreparedStatements are indeed very good candidates for batching, and some of the database systems (e.g. Oracle) support batching only for prepared statements.
- Since the JDBC defines a distinct API for the batching (for e.g. PreparedStatement.addBatch and PreparedStatement.executeBatch), if you are generating statements manually, then you should know right from the very start whether you should be using batching or not. With Hibernate, you can easily switch to batching with a single configuration.
- Hibernate 5.2 offers us with Session-level batching, so it’s even more flexibile in this front.
-
Statement caching
- Statement caching is one of the least-known performance optimizations that you can very easily take advantage of. Depending on the underlying JDBC Driver, you can cache the PreparedStatements both on the client-side (the Driver) or the databases-side (either the syntax tree or even the execution plan).
-
Hibernate identifiers
- When you are using Hibernate, the IDENTITY generator is not a very good choice since it disables the JDBC batching.
- TABLE generator is even worse as it uses a separate and individual transaction for fetching a new identifier, which can put a lot of pressure on the underlying transaction log, as well as the connection pool as a separate connection is required every time we need a brand new identifier.
- SEQUENCE is the right choice, and even SQL Servers supports since version 2012. For the SEQUENCE identifiers, Hibernate has been offering optimizers like pooled or pooled-lo which can reduce the number of database roundtrips by multifold required for fetching a new entity identifier value.
-
Choosing the appropriate column types

- You should always use the correct column types on the database side. The more compact the column type is, the more entries can be inculcated and accommodated in the database working set, and indexes will better fit into the memory. For this very purpose, you should take advantage of database-specific types (e.g. inet for IPv4 addresses in PostgreSQL), especially due to the fact that Hibernate is very flexible when it comes to implementing a new custom Type.
-
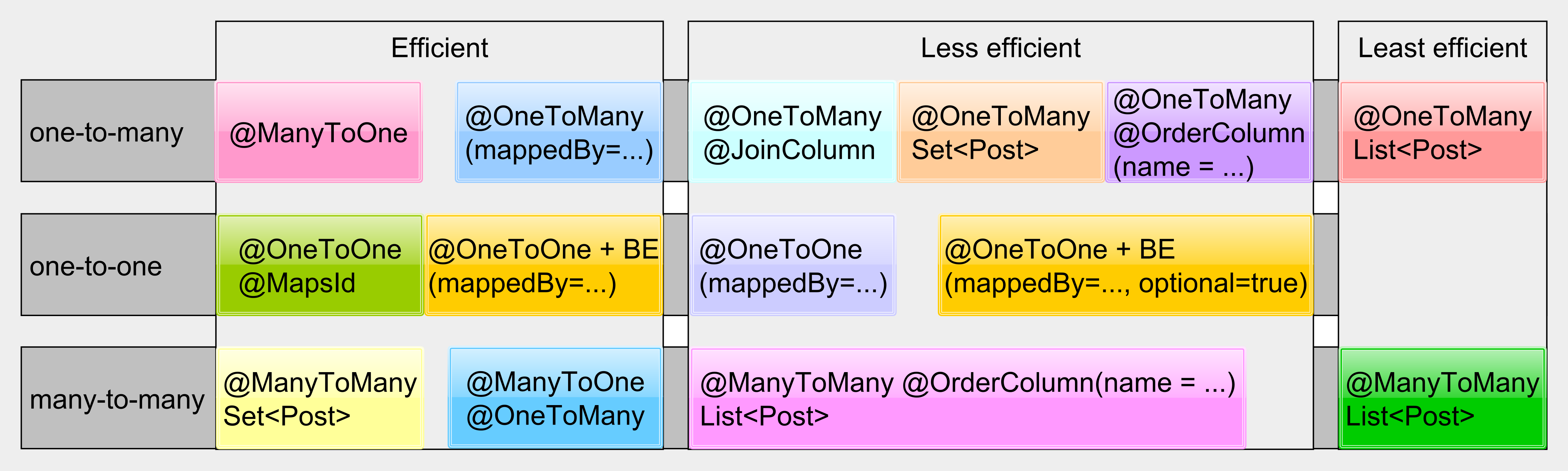
Relationships
- Hibernate comes with many relationship mapping types, but not all of these are equal in terms of the efficiency.
- Unidirectional collectionsand the @ManyToMany List(s) should be avoided at any cost. If you really need to use entity collections, then the bidirectional @OneToMany associations are generally preferred. For the @ManyToMany relationship, use the Set(s) since they are more efficient in this case or simply map the linked many-to-many tables as well and turn the @ManyToMany relationship into two different bidirectional @OneToMany associations.
- However, unlike the queries, collections are a lot less flexible since they cannot be easily paginated; the meaning of this statement is that we cannot use them when the number of the child associations is rather high. For this very reason, you should always question if a collection is really vital or necessary. An entity query might be a better alternative in many of the situations.
-
Inheritance
- When it comes to the topic of inheritance, the impedance mismatch between the object-oriented languages and the relational databases becomes even more apparent. JPA offers us with a SINGLE_TABLE, JOINED, and TABLE_PER_CLASS to deal with the inheritance mapping, and each of these strategies has plus points as well as minus points.
- SINGLE_TABLE performs the best in the terms of SQL statements, but we lose a lot of the data integrity side since we cannot use NOT NULL constraints in this case.
- JOINED addresses the data integrity limitation while also offering more complex statements. As long as you do not use polymorphic queries or @OneToMany associations against the base types, this strategy works just fine. Its true power comes from the polymorphic @ManyToOne associations backed by a Strategy pattern on the data access layer side.
TABLE_PER_CLASS should be avoided as it does not render efficient SQL statements.
-
Persistence Context size
- When you are using JPA and Hibernate, you should always make sure you are minding the Persistence Context size. For this very reason, you should never bloat it with tons of managed entities. By restricting the amount of managed entities, we gain a better memory management, and the default dirty checking mechanism is going to be a lot more efficient as well.
- Thank you very much for reading this blog and if you have any queries please feel free to come up with them! I hope you have a wonderful rest of your day!!
- For More Information on Real time Projects and infomation like this make sure to register yourself at NullClass now !
Read Related Articles :
0 responses on "High-Performance Java Persistence Tips"